Inside the PAXIO Network Redesign: One BGP Design, Zero Outage
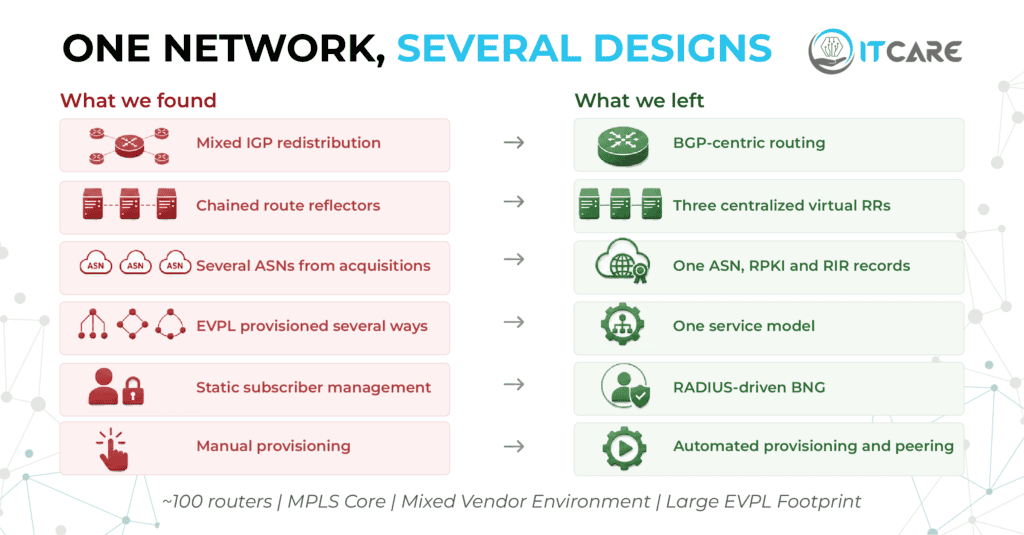
Inside the PAXIO Network Redesign: One BGP Design, Zero Outage Some networks are designed. Others accumulate. PAXIO ran business fiber in the Bay Area, and their network had grown the way a lot of provider networks grow, through acquisitions. Around 100 routers in the MPLS core, a mixed vendor environment, and a large EVPL footprint […]
Nobody pushes a config change at 17:00 on a Friday twice.

Nobody pushes a config change at 17:00 on a Friday twice Nobody pushes a config change at 17:00 on a Friday twice. The first time teaches you everything you need to know. The link comes up, the BGP session comes up, the graphs look clean, and then somewhere around Saturday morning a customer opens a […]
“Call everyone” is not an escalation policy.

“Call everyone” is not an escalation policy. When something breaks at 3am and the response is to page the whole team onto a bridge, that is not escalation. It is a panic broadcast. An incident escalation process is a designed system, and this is what happens when nobody designs it. The failure modes are predictable: […]
MONITORING SYSTEMS PROBLEM
MONITORING SYSTEMS PROBLEM The number one problem we find when we onboard a new network is not the routing. It is the monitoring. Most conversations about network monitoring best practices start with tool selection. Ours starts somewhere else, because the tool is almost never the problem. At first glance every setup looks fine. Someone spun […]
OUTSOURCED NETWORK MONITORING: WEEK-ONE CHECKLIST

OUTSOURCED NETWORK MONITORING: WEEK-ONE CHECKLIST A network that has been stable for three years is not one we trust yet. Stable often just means nobody has touched the part that is quietly broken. That assumption shapes how we run every outsourced network monitoring engagement. When we take over monitoring for a new ISP, data center, […]
ISP DDoS Protection: Why ITcare Partnered With Corero

ISP DDoS Protection: Why ITcare Partnered With Corero DDoS protection is not one product. It is the right mix for the network in front of you, deployed properly and kept running. This week ITcare became a partner of Corero Network Security, a premium-tier DDoS detection and mitigation platform. SmartWall ONE is always on and automated, […]
NetBox Integration and Deployment: ITcare Joins NetBox Labs

NetBox Integration and Deployment: ITcare Joins NetBox Labs We are glad to share that ITcare is now an official partner of NetBox Labs, the company behind the NetBox Labs platform, one of the most widely used platforms for network source of truth and infrastructure automation. Over the past years our team has delivered multiple projects […]
NEXT GENERATION NETWORK EQUIPMENT DELIVERED

NEXT GENERATION NETWORK EQUIPMENT DELIVERED One more happy client and another important project in progress. We were pleased to deliver a new batch of next generation Juniper Networks equipment, ready for the next stage: configuration, integration, and production deployment. The delivery includes Juniper MX304 next generation routers, together with high performance interfaces and optical modules, […]
SUCCESSFUL COMPLETION OF OUR ANNUAL ISO AUDIT

SUCCESSFUL COMPLETION OF OUR ANNUAL ISO AUDIT Over the past weeks, we successfully completed our annual internal ISO audit, an important milestone in our continuous effort to maintain high standards of quality, efficiency, and compliance. As part of this yearly verification process, our team presented the updated documentation and current activity records, ensuring that all […]
BUILT FOR CONNECTIVITY PROVIDERS. NOT GENERIC IT.
BUILT FOR CONNECTIVITY PROVIDERS. NOT GENERIC IT. We built ITcare for connectivity providers. Not general IT. Not a help desk with network awareness. Engineers who live in this space. 2 things our clients come back to most: 👉 24/7 NOC – L1, L2, and L3 coverage. Cisco, Juniper, AWS, and Kubernetes certified. Real-time anomaly detection, incident […]