MONITORING IS A CORRELATION PROBLEM, NOT A DASHBOARD PROBLEM
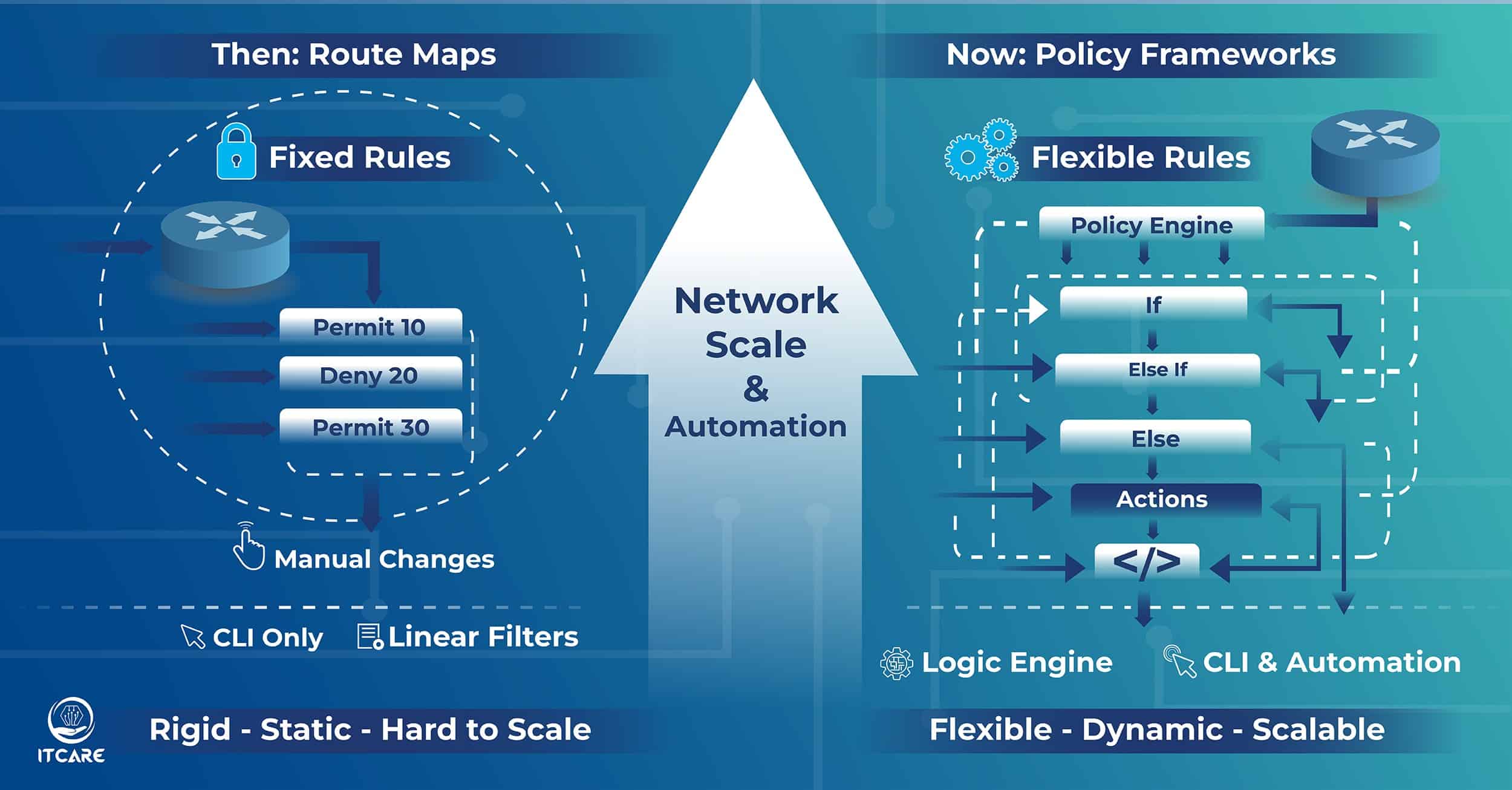
Many teams today run five or six monitoring tools at the same time. They use LibreNMS for one part, Nagios for another, Icinga for alerts, PRTG or SolarWinds for graphs, and then a few custom scripts on the side. Each tool does what it is supposed to do, but none of them tell a complete story. You get alerts, you get graphs, you get logs, but you do not get a connected picture of what actually caused the issue. This leads to long incidents, slow root cause analysis, and teams guessing instead of knowing.
The real problem is not the tools. The problem is that these tools do not talk to each other in a meaningful way. They do not correlate symptoms across layers. They do not match a routing flap with a throughput drop. They do not tie a device warning to an application impact. They do not show the chain of events in the order that matters. Because of this, engineers start each incident with a pile of raw signals and no clear direction.
At ITcare, we treat monitoring as a correlation problem, not a dashboard problem. We combine data from different sources and build a timeline that makes sense. We link alerts with network paths. We connect device health with actual service impact. We use our processes and automation to create a single operational story. This is also why we are able to resolve about 90 percent of incidents within the first 10 minutes. Our engineers do not waste time switching between tools and guessing which symptom matters. They start with context and act immediately.
A noisy monitoring stack does not make you safer. A correlated one does. If you want faster resolution and fewer surprises, focus less on adding new dashboards and more on connecting the information you already have.