case studies
Designing Webdock's New DC: EVPN-VXLAN Multi-Vendor Fabric
Designing Webdock's New Data Center: A Multi-Vendor EVPN-VXLAN Fabric Built for Hosting
Customer Story
Webdock is a Danish cloud hosting provider serving customers across Europe and beyond with VPS, bare metal, and managed hosting infrastructure. As their customer base grew, they made the decision to build a new data center from the ground up, purpose-designed for the multi-tenant mix of virtualized and bare metal workloads they expected to serve at scale.
Building the physical data center was their responsibility. Building everything that runs inside it was ours. The brief covered the network architecture, hardware selection, services design, automation, and the ongoing operational capability to support both their team and their customers around the clock. Webdock needed a partner who could deliver all of that not as separate engagements handed off between teams, but as a single coherent design that the same engineers would also run in production.
Design / Engineering
Published: May 1, 2026
Client: Webdock
Industry: Data Center
Solution
The brief
Webdock’s requirements shaped every decision. They needed:
- Multi-tenancy at scale, mixing virtualized workloads (VMs and VPS) with bare metal servers in the same fabric.
- Predictable, deterministic forwarding with no Layer 2 surprises.
- Active-active redundancy at the server level, with no Spanning Tree dependencies.
- The ability to stretch a Layer 2 segment between customer instances on demand, regardless of whether those instances were VMs or bare metal.
- Automation from day one. Manually provisioning servers and racks at the scale Webdock plans to grow to was never an option.
- A design that does not lock them into a single vendor.
Those six points map directly to the choices we made next.
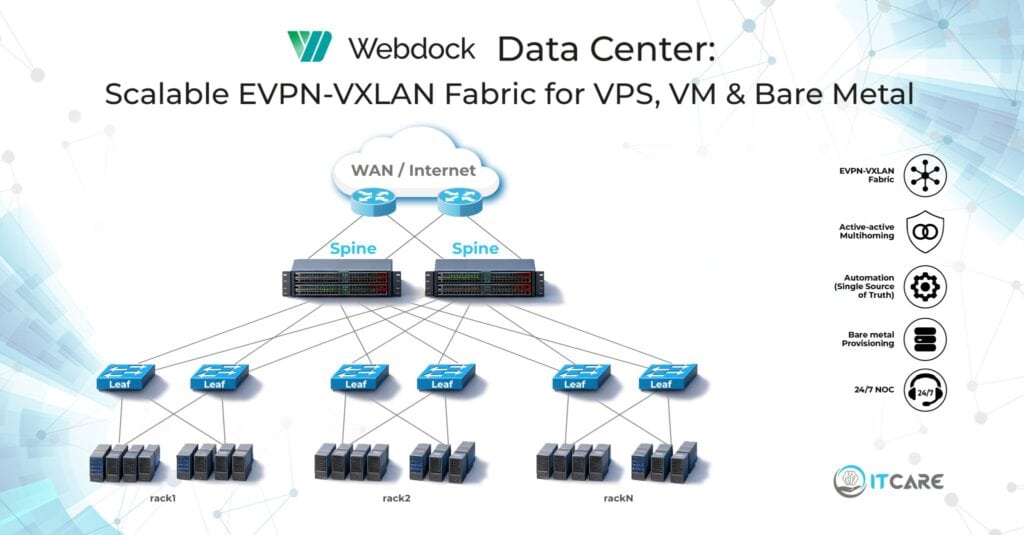
Why a pure EVPN Type 5 IP Fabric at the underlay
We chose a classic Spine-Leaf IP Fabric, but with one deliberate decision that shapes everything downstream: a pure EVPN Type 5 design at the fabric layer.
In a Type 5 fabric, the underlay advertises only IP prefixes, not MAC addresses. The fabric becomes a fast, scalable, deterministic L3 forwarding plane. No MAC learning at scale. No BUM traffic (broadcast, unknown unicast, multicast) flooding through the fabric. No Layer 2 control-plane surprises that take a senior engineer half a day to diagnose.
This is the cleanest possible separation between fabric and tenant overlay. The fabric does one job, forward IP packets between VTEPs, and it does that job predictably. Tenant Layer 2 services live entirely in the overlay, originated by VTEPs that sit closer to the workload.
For anyone evaluating fabric designs, this is the single decision with the most operational consequence over a five-year horizon. A fabric that has to learn tenant MACs at scale will eventually surprise you. A fabric that only forwards IP will not.
Pushing VXLAN to the hypervisor
The second decision is the one that makes the design work specifically for a hosting provider: VXLAN encapsulation originates at the hypervisor, not at the leaf.
When the hypervisor is part of the EVPN-VXLAN and serves as VTEP, every tenant network is a logical construct decoupled entirely from the physical fabric. A VM coming up on a host immediately becomes a member of its tenant VNI, with no leaf-side change. A VM migrating between hosts keeps its addressing and adjacency, again with no leaf-side change. The leaf does not need to know which tenants exist on which servers. It only needs to deliver IP packets between hypervisor VTEPs.
For bare metal, where the hypervisor abstraction does not apply, we extend the same logic by terminating the relevant VNI at the leaf for that specific bare metal port. The result is a uniform tenant model regardless of whether the workload runs on a VM, a VPS, or a bare metal server.
This is what makes the design honest. A hosting provider sells a mix of products to a mix of customers, and the fabric should not care about the difference.
Active-active multihoming with EVPN ESI
Every rack in the design has dual Arista leaves. Every server, whether a hypervisor or a bare metal node, connects to both leaves over an active-active bond.
We implemented this with EVPN Ethernet Segment Identifier (ESI) multihoming. ESI gives us:
- True active-active forwarding on both uplinks, not active/standby.
- No reliance on Spanning Tree or proprietary MLAG-style protocols.
- Sub-second convergence on link or leaf failure.
- Independent upgrades. A leaf can be taken down for maintenance without taking down the rack.
The control plane for this lives in EVPN. The leaves advertise ESI routes between themselves so they coordinate which one forwards a given flow. From the server’s perspective, the bond is a single logical attachment. From the network’s perspective, no proprietary clustering technology is in the path.
Why Arista leaves, Juniper QFX5200 spines, and MX480 edge
Mixing vendors was deliberate. Each layer of the design has different requirements, and the best tool for each layer is not always the same tool.
Arista leaves. The leaf layer carries the bulk of the east-west traffic and is the most operationally active part of the fabric. Arista’s eAPI and CloudVision give us a clean automation surface. The EVPN-VXLAN implementation has been mature for years. The hardware handles the high east-west traffic profile typical of hosting workloads without compromise.
JuniperQFX5200 spines. The spine has one job: forward IP between leaves at line rate. The QFX5200 is purpose-built for that, with high-density 100G and the right buffer profile for a pure L3 transit role. We do not want spines doing anything else, and the QFX5200 does not try to.
Juniper MX480 edge. The edge router needs to do everything spines and leaves do not: peering with multiple upstream providers, deep route tables, advanced policy, BGP communities, RPKI ROV, optional MPLS or segment routing for future DCI, DDoS hooks. The MX480 has the forwarding performance and the feature depth to do all of that without compromise.
Mixing vendors looks complex at first glance. With a strong automation layer underneath, it is not. Each device type has a templated configuration model and a tested provisioning flow.
Intent and Source of Truth: defining the network, then applying it
The architectural decisions above describe what the network is. Just as important is how it is operated. Every configuration on every device in Webdock’s data center is derived from a single Source of Truth.
The Source of Truth holds intent. It describes what the network should look like and what services should be running on it: which racks exist, which leaves and spines they contain, how those devices interconnect, which tenants exist, which VNIs they use, which servers belong to which tenants, which L2 extensions are active, and so on. The Source of Truth is the canonical description of the intended state of the network.
The network itself does not hold the truth. It reflects it. Configuration is generated from the Source of Truth and rendered onto each device by automation. When intent changes, the change is made in the Source of Truth first, then propagated to the devices that need it. When the network’s actual state drifts from the intended state, the automation reconciles it back.
This is the operational pattern often called Intent-Based Networking. The shorthand: define what you want, let the automation figure out how to apply it, and let the system continuously verify that the network matches the intent.
In practice this gives us:
- A new device added to inventory in the Source of Truth picks up the right base configuration automatically when it boots.
- A new tenant defined in the Source of Truth gets the right VNIs configured on every relevant device.
- A new bare metal customer is not configured by writing CLI on switches. It is configured by adding the customer to the Source of Truth, and the network applies the result.
- Configuration drift is detected, because the automation knows what the network should look like and can compare it with what it actually looks like.
- Audits become trivial, because the Source of Truth is a single document of record. The state of any device is reproducible from it alone.
For a hosting provider with multi-tenant infrastructure, this is the only practical way to operate at scale. Hand-configured networks scale until the operator burns out. Intent-driven networks scale with the business.
On-demand Layer 2 extension between customer instances
Hosting customers occasionally need Layer 2 adjacency between their instances. A cluster heartbeat. A legacy application that assumes broadcast adjacency. A database with multicast requirements. The fabric needs to support this on demand, regardless of whether the instances are VMs on different hypervisors or bare metal nodes in different racks.
We built this as an automated workflow. The customer, or the Webdock platform on their behalf, requests an L2 segment between specific instances. The automation determines where those instances live, configures the matching VNI on the relevant hypervisor VTEPs or leaf ports, and brings the segment up.
For VMs, this means adjusting the hypervisor’s tenant configuration. For bare metal, it means pushing the right VNI to the leaf-side port. From the customer’s perspective, the result is identical: their instances see each other on the same broadcast domain.
This is a feature competing hosting providers either do not offer, or offer with manual coordination and lead time. With this automation, it is a self-service operation.
Automated bare metal provisioning with DHCP and PXE
Bare metal provisioning is where most hosting providers run into walls. A new physical server arriving in a rack is traditionally a high-touch, multi-step process involving cabling, BIOS work, OS installation, network configuration, and integration with billing and monitoring.
We built this as a single automated flow. When the server is racked and powered on:
- The server boots over PXE.
- The leaf port it is connected to delivers DHCP that routes the boot request to the provisioning system.
- The provisioning system identifies the server by MAC, looks up its assignment (tenant, OS image, network configuration), and delivers the right OS image.
- During first boot, the network configuration is applied. The leaf port is moved into the correct tenant VNI. The server registers with inventory and monitoring.
- The server is in production within minutes of being racked.
The same automation pipeline handles new rack provisioning. When a rack is built, the rack’s leaves are inventoried, base configuration is pushed, BGP sessions to the spines come up, and the rack is ready to accept hypervisors and bare metal.
After the build: 24/7 NOC and ongoing operations
Designing and deploying a data center is the start of the relationship, not the end of it. Once the fabric was in production and the automation was operating, ITcare moved into the operational role as well. Today, our 24/7 Network Operations Center monitors Webdock’s data center continuously, manages incidents, handles change requests, and supports the network side of customer operations around the clock.
This continuity is intentional. The engineers who designed the fabric are the same engineers who supervise its operation. Knowledge does not get lost in a handover from a “design phase” to an “operations phase.” The Source of Truth, the automation, and the runbooks are all built and maintained by the team that runs them.
For Webdock, this means one partner across the lifecycle. For their customers, it means the people answering the ticket at three in the morning understand exactly how the network is built and why each decision was made.
What this design gives Webdock
A network that grows with the business without growing the operational overhead.
A new rack is not a manual configuration project. A new bare metal server is not a ticket queue. A new tenant is not a coordination meeting between teams. The architecture and the automation absorb the routine work, and Webdock’s team focuses on the parts of the platform that are unique to their product.
The fabric is multi-vendor, but the operational experience is uniform because the automation layer treats each vendor as a target with a defined interface. The tenant model is unified, because the hypervisor and the leaf both speak the same overlay language. Layer 2 extension is on-demand, because the automation composes VNIs between any two points in the fabric.
Closing thought
Data center fabrics are still often built the way they were ten years ago. A pile of L2 underneath. A pile of features layered on top to make it sort of work for cloud workloads. That approach scales until it does not.
Building a fabric properly today means making three commitments. The fabric does L3 and only L3. The overlay does tenancy and only tenancy. The automation owns provisioning and only provisioning. Each layer has one job. When each layer has one job, the whole system becomes predictable, debuggable, and extendable.
Webdock’s new data center is a working example of those three commitments. We are proud to have designed it.
If you are building or rebuilding a data center fabric for a hosting platform, an ISP, or a cloud provider, we would like to talk. Whether you need a design partner, a 24/7 NOC once it is live, or both, get in touch.
be our next success story!
Drop us a line! We care for your Business and are here to answer your questions 24/7