BGP ROUTE REFLECTORS BEYOND THE WHITEBOARD
Route Reflector placement looks simple on a whiteboard. Until you run it in production.
𝗜𝗻-𝗽𝗮𝘁𝗵, typically on a P router that already handles transit. Or out-of-path, a dedicated virtual appliance doing only route reflection.
We lean out-of-path almost every time.
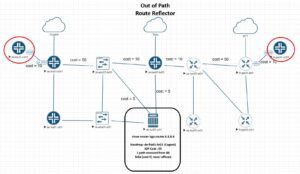
𝗢𝘂𝘁-𝗼𝗳-𝗽𝗮𝘁𝗵, the RR is a control plane only node. No forwarding decisions, no Forwarding Plane overhead, full CPU dedicated to BGP, RIB-in, RIB-out and policies. A converged vRR easily handles 8-12M paths even under heavy churn.
The catch is best-path consistency. RFC 4271 defines the decision process. By the time you reach the IGP metric tiebreaker, you have filtered on LOCAL_PREF, AS_PATH, ORIGIN, MED, and eBGP over iBGP.
If paths are still tied, IGP metric to the BGP next-hop decides. That metric is computed from the RR’s IGP position, not the client’s. A central vRR sees exit A as closer, while a client in another POP would prefer exit B. Result, sub-optimal hot-potato.
You can try to disable the IGP step, but vendor support is uneven:
– Cisco IOS/XE/XR: bgp bestpath igp-metric ignore
– Huawei VRP: bestroute igp-metric-ignore
– Arista EOS: no direct equivalent I am aware of
– Juniper Junos: in my experience I have not found one
– Nokia SR OS: never tried, not sure if a knob exists
If I missed the right command for any vendor, drop it in the comments.
Even when the knob exists, it shifts the decision to router-ID. Operationally useless, but at least consistent.
The real fix is BGP Optimal Route Reflection. ORR runs the decision process from a configured IGP location per client, so the reflected best path matches what the client would have picked itself.
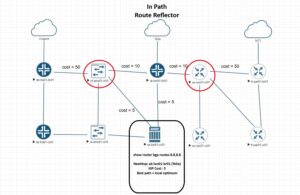
𝗜𝗻-𝗽𝗮𝘁𝗵 𝗥𝗥 𝗽𝗿𝗼𝘀: no extra hardware, best-path matches forwarding, faster signaling.
𝗜𝗻-𝗽𝗮𝘁𝗵 𝗥𝗥 𝗰𝗼𝗻𝘀: the P router becomes control-plane critical. Modern boxes split CP and DP CPUs, but things like BFD are the critical to handle. Depending on platform and config, BFD runs on the line card / forwarding ASIC (hardware-offloaded) or on the route engine CPU. Hardware BFD survives a CP spike. CPU BFD is more flexible but tied to the same cores handling BGP, SNMP and SSH. Leave defaults on a busy in-path RR, and a CP storm can flap BFD sessions, taking fast-reroute and convergence with them.
𝗢𝘂𝘁-𝗼𝗳-𝗽𝗮𝘁𝗵 𝗥𝗥 𝗽𝗿𝗼𝘀: isolation, cheap x86, painless upgrades, zero traffic impact when draining.
𝗢𝘂𝘁-𝗼𝗳-𝗽𝗮𝘁𝗵 𝗥𝗥 𝗰𝗼𝗻𝘀: hot-potato sub-optimality without ORR, more BGP runs per-client, slightly higher cold-start convergence.
RR-to-RR peering, cluster-IDs, ADD-PATH, ORR are all separate rabbit holes. Herve Hildenbrand has a solid breakdown of BGP PIC Edge, ADD-PATH and BGP-ORR. I will share my take on cluster-ID design in a separate post.
That said, curious to hear what others prefer. In-path or on the side?