case studies
Monitoring & Alerting
Monitoring project
Customer Story
A significant challenge many of our customers face is a lack of visibility into their networks. This gap not only led to decreased performance but also elevates risks.
Recognizing this, the first step in our customer onboarding process often involves integrating a well-defined Network Monitoring System (NMS). Without a NMS in place, you are blind, troubleshooting takes forever, and is hardly impacting customer experience.
Therefore, designing and deploying a scalable solution for monitoring is a foundational step which is crucial for ensuring operational continuity, enhancing performance, visibility on the infrastructure and security.
Monitoring
Published: Feb 23, 2023
Client: Non Disclosure
Industry: Enterprise

Solution
Open-Source Monitoring Solutions
Through our extensive experience, we’ve observed a clear preference among our clients for open-source monitoring solutions.
Generally speaking, we observed a clear trend towards adopting open-source stacks. This trend is driven by the numerous benefits that open-source offers, chief among them the flexibility to integrate with existing systems and technologies. Through open APIs and the ability to customize with own blocks of code, organizations can maintain operational continuity with minimal disruption.
Open-source solutions empower businesses to adapt and innovate, ensuring that their operations remain agile and responsive to different demands.
Driven by customer requests and decisions, our focus has sharpened on automating, improving, and creating scalable solutions for two leading systems: Zabbix and Prometheus. These platforms have emerged as the go-to choices for their flexibility, robustness, and cost-effectiveness.
Zabbix: A Scalable Monitoring Powerhouse
Zabbix excels in its ability to monitor virtually any system, application, or device. It uses a disaggregated architecture that makes it a very scalable solution that can easily expand to facilitate infrastructure demands. At ITcare we had multiple projects deploying Zabbix as a scalable solution and one of thus, we would like to explore below. The architecture encompasses multiple elements:
Zabbix Server: The Zabbix Server is the central processor of the monitoring environment. It is primarily responsible for collecting and processing data, executing scripts, sending notifications, and rendering the front-end for user access. For scalable architecture, usually Zabbix Server is not capable of handling the entire load, therefore it requires some Zabbix Proxies(we will talk about proxies at a later stage).
Zabbix Database: For the Zabbix DB, there is a flexibility in choice. MySQL, PostgreSQL, Oracle, and SQLite are all supported, with MySQL and PostgreSQL being the most commonly used. These databases serve as the backend, storing all configuration data, statistical data, and historical data that the Zabbix Server processes.
Zabbix Proxy: A Zabbix Proxy is designed to collect performance and availability data on behalf of the Zabbix Server. This allows for distributed monitoring, reducing the load on the central server, and enabling scalability across geographically dispersed environments. Proxies can operate autonomously, managing local data collection even if the connection to the main server is temporarily lost.
Interfaces and Zabbix templates:
Provides various interfaces to collect metrics, such as:
Zabbix SNMP Agent: Utilizes the Simple Network Management Protocol to monitor network-attached devices.
Zabbix Agent: A software installed on any OS that monitors local resources and applications on a host. On the Zabbix Agent, custom scripts can be developed to collect specific metrics, providing the flexibility to monitor almost anything within your IT environment and reflect this data within Zabbix.
Zabbix IPMI: Uses the Intelligent Platform Management Interface for hardware health monitoring.
Each interface comes with a range of predefined templates for different vendors, significantly simplifying the setup process. The vibrant Zabbix community also actively contributes to the pool of templates, continuously expanding support for new devices and applications.
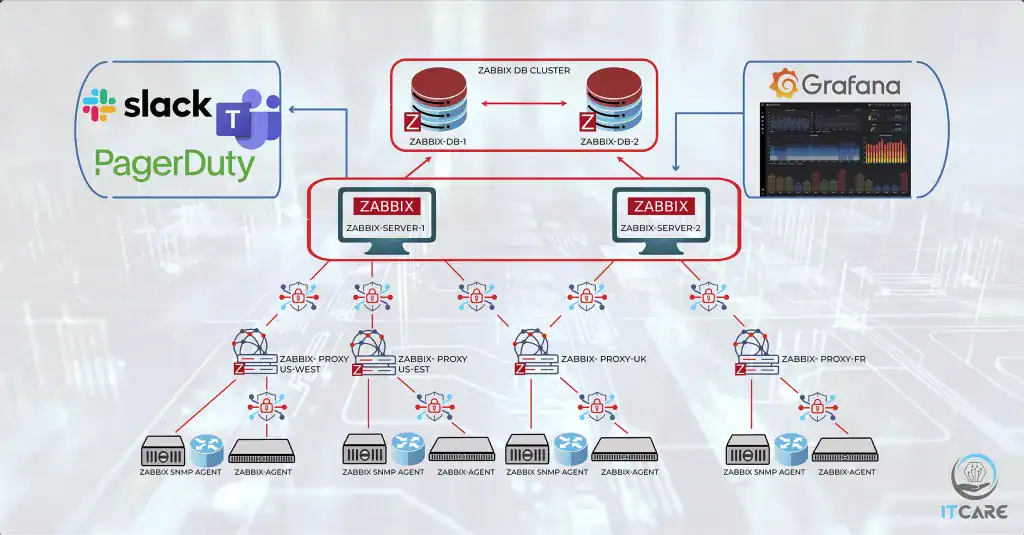
Customized Scalable Zabbix Architecture
For one of our esteemed customers, we successfully deployed a scalable Zabbix architecture that included a cluster of Zabbix Servers with native HA function that sends keepalives to Zabbix DB informing about the state of each server.
For the backend we used a cluster of Zabbix DB nodes running PostgreSQL(based on customer request). We strategically placed Zabbix Proxies across different regions, such as US East, US West, EU United Kingdom, and EU Frankfurt.
These proxies gathered data from Zabbix Agents and SNMP Agents, funneling it to the Zabbix Server, which then pushed all the collected information to the database.
Enhancing visibility with Grafana
Further enhancing the monitoring solution, we integrated Grafana to pull data from the Zabbix DB, presenting it on customized dashboards. These dashboards provided regional, service-specific, and infrastructure-specific views, along with other tailored visualizations to offer deeper insights into the network’s status.
Incorporating Slack and PagerDuty for Alert Management
To augment the NMS with efficient alert notifications, we incorporated Slack webhook. This integration ensured that all alerts were promptly communicated to the Operations team, keeping them informed about critical infrastructure events.
Additionally, we integrated PagerDuty to dispatch SMS notifications for alarms with ‘Disaster’ severity directly to a specialized contact group, alerting them about priority zero (P0) incidents.
Prometheus: The Open-Source Monitoring Framework of Choice
Another case of a Open-Source NMS implementation falls to the choice of Prometheus. Prometheus is an open-source system monitoring and alerting toolkit that has become the de-facto standard for time-series data collection and processing. It’s known for its simple yet powerful model for aggregating and querying metrics, as well as its ease of use..
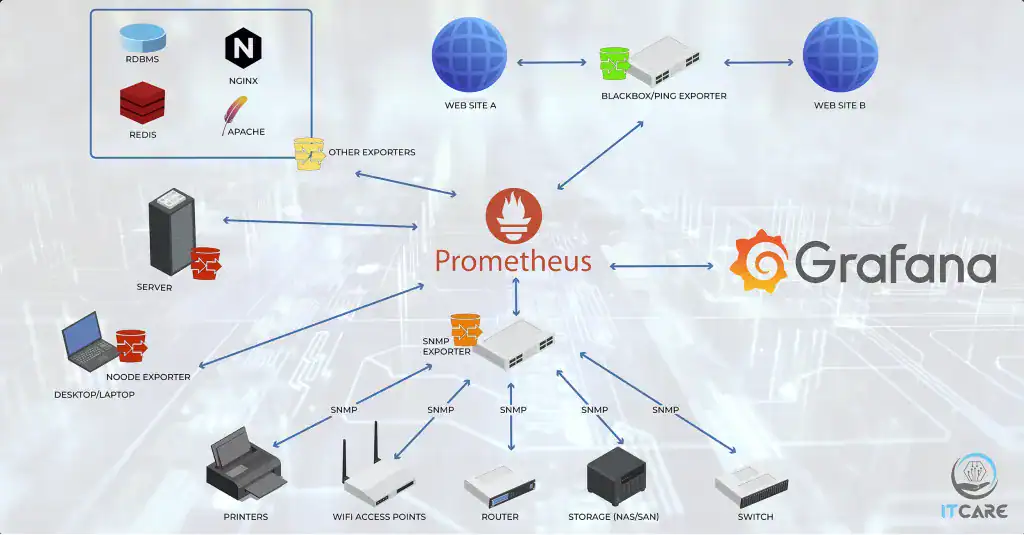
Prometheus Architecture: Designed for Reliability and Scalability
Prometheus’s architecture is modular and decentralized, comprising several components that work together to gather, store, and process data. At its core, the Prometheus server scrapes and stores time-series data. Its data model and query language, PromQL, provide a flexible and powerful way to select and aggregate this data.
Storage Efficiency with Prometheus
Prometheus typically uses a local on-disk time series database but can also integrate with remote storage systems. While it does not dictate a specific database system, it is often paired with longer-term storage solutions like Thanos or Cortex to enhance its scalability and durability.
Data Collection: Diverse and Extensive
Collects metrics using various service discovery mechanisms, allowing it to dynamically monitor your services:
Prometheus Node Exporter: For monitoring the host machine’s metrics.
SNMP Exporter: For collecting metrics from network devices using SNMP.
Blackbox Exporter: For probing endpoints over HTTP, HTTPS, DNS, TCP, and ICMP.
These exporters are accompanied by an extensive range of predefined templates and are supported by a robust community that contributes additional configurations for a vast array of services and applications
Push Gateway for Ephemeral Jobs
Prometheus also offers a Push Gateway for monitoring short-lived jobs. While it primarily uses a pull model for stability and control, the Push Gateway enables pushing data for scenarios where scraping is not possible. network’s status.
Custom Options with Exporters
Prometheus’s flexibility is further exemplified by the ability to create custom exporters when existing ones do not cover specific monitoring needs. This allows for tailored metric collection, ensuring comprehensive monitoring of all aspects of the infrastructure.
Prometheus Architecture Case Study
For one of our clients, we deployed a scalable Prometheus solution. We utilized a federated cluster of Prometheus servers for high availability, ensuring no single point of failure.
Each server was responsible for a specific part of customer’s infrastructure, since all customers POPs were located in the US we deployed in on a per-state basis, NY, NJ, OH and MI. The primary scope of Prometheus was to monitor different applications with specific Prometheus Exporter, but besides that we also added simple SNMP Exporter to monitor network endpoints.
We ended up with a very robust monitoring solution, integrated it with Grafana for a better visibility and Grafana on-call for alerting. Everything was automated based on labels, so that it can easily scale and integrate with new nodes and meet growth demand.
One of the key strategies that significantly enhanced our speed of integration was leveraging automation through Ansible playbooks. That automation played a pivotal role in deployment, integration as well as time and cost savings.
Based on increased demand on Open-Source monitoring solutions, we focused primarely on Zabbix and Prometheus to define specific Ansible roles and playbooks that will help us and will make our customers happy. Coupled with custom Zabbix templates and finely tuned settings for Prometheus
Exporters, we’ve managed to streamline the deployment process across various systems, vendors, and services. This approach not only saved time but also improved the efficiency and reliability of the monitoring solutions we implemented.
Once the deployment of monitoring systems like Zabbix or Prometheus is complete, the journey into deep data analysis begins.
The standard set of metrics typically includes indicators of system health and performance such as Power Status, Power Consumption, Fan Status, CPU Usage, Load Average, Memory Utilization, Disk I/O, Interface Bandwidth Utilization, Interface Errors, and Discards/Drops, as well as BUM (Broadcast, Unknown unicast, Multicast) traffic on interfaces.
However, to truly tailor the monitoring experience, additional metrics are often essential, including:
– HTTP Response Time, for web service availability,
– DNS Query Resolution Time, ensuring domain name resolution is functioning optimally,
– Database Query Performance, to monitor the speed and efficiency of database operations,
– Application-Specific Transaction Times, to measure the performance of critical business processes,
– SSL Certificate Validity, to prevent unexpected certificate expirations,
– Custom Application Logs, for insights into application-specific events or errors,
– Queue Lengths for messaging systems, to avoid bottlenecks in data processing.
These metrics are just the beginning. Depending on the unique landscape of the applications in use, further customized metrics may include:
– API Endpoint Availability and Latency, for service-oriented architectures,
– User Experience Metrics, such as page load times and interaction delays,
– Cloud Resource Utilization, to optimize spend and performance in cloud environments,
– Kubernetes Cluster Metrics, for those utilizing container orchestration,
– Security Metrics, such as the number of failed login attempts or unusual traffic patterns.
At this stage, the Operations Team becomes a crucial player, engaging in daily reviews, analysis, and continuous updates to enhance the monitoring systems. Their goal is not only to improve visibility but also to shorten reaction times to various events. This iterative process of monitoring, reviewing, and improving is vital to maintaining a robust and responsive IT infrastructure.
be our next success story!
Drop us a line! We care for your Business and are here to answer your questions 24/7