case studies
Killing the Shared VLAN: IP Mobility for a Cloud and Hosting Provider
IP Mobility for a Cloud and Hosting Provider
From Shared VLAN to rEAL Tenant Isolation
Most multi-tenant hosting networks start the same way. You carve a few /24 prefixes, drop them on a shared VLAN, and let every VM, container, and bare metal server share one broadcast domain. It is fast to stand up, it is easy to reason about on day one, and it works right up until the point where it becomes the single biggest security and operability problem in the network.
We recently rebuilt the access network for a cloud and hosting provider that offers VMs, containers, and bare metal servers from the same infrastructure. This post walks through the design decisions we made, why we made them, and how the final architecture delivered IP mobility as a side effect of getting the security model right
Design / Engineering
Client: Non Disclosure
Industry: Cloud & Hosting
Services: Professional Network Services, Network Automation
Technologies: MP-BGP, BGP, IPv6, cloud-init, Layer 3 routing, IP mobility
The problem with the shared VLAN
The starting point was a classic shared Layer 2 design. Several /24 prefixes lived on one VLAN, and every tenant workload sat in the same broadcast domain. Different customers, different trust levels, one flat segment.
The issue was not capacity or addressing. It was that a shared broadcast domain hands every tenant the tools to attack every other tenant. On a flat segment you are exposed to the full Layer 2 threat surface:
- ARP spoofing, where a malicious workload claims another tenant’s IPv4 address and intercepts or blackholes their traffic.
- MAC spoofing, where a workload impersonates another endpoint’s hardware address.
- IPv6 Neighbor Discovery spoofing, the v6 equivalent of ARP poisoning, often overlooked because IPv6 gets bolted on after the v4 design is already set.
- Rogue Router Advertisements and a long tail of other broadcast and multicast abuse.
You can push back on some of this. MAC ACLs and IP ACLs at the switch can pin a port to an expected address pair, and features like dynamic ARP inspection or DHCP snooping help on managed switches. But two things make this approach a losing battle in a hosting environment.
First, the enforcement point is wrong. The workloads do not connect to physical switch ports. They connect to virtual interfaces inside a hypervisor or container host. The switch sees the host’s uplink, not the individual TAP interfaces behind it. To properly police Layer 2 you have to enforce at the hypervisor level, and doing that reliably across mixed virtualization and container stacks is genuinely hard. You end up maintaining brittle ebtables or nftables rules, per-bridge filtering, and anti-spoof logic that has to be kept in sync with provisioning. Every new workload type is a new edge case.
Second, even when it works, you are patching a design problem rather than removing it. The broadcast domain is still there. You are spending engineering effort to make a fundamentally shared and trusting medium behave as if it were isolated.
We decided not to harden the shared VLAN. We decided to delete it.
The decision: Layer 3 to the host
The core design choice was to stop treating the host as a Layer 2 bridge into a shared segment, and instead treat each host as a Layer 3 routed system that speaks BGP to the fabric.
Every host runs MP-BGP and peers with the fabric. MP-BGP matters here because the design is dual-stack from the ground up. The same BGP sessions carry both IPv4 and IPv6 reachability, so v6 is a first-class citizen rather than an afterthought layered onto a v4 design.
Each tenant workload, whether a VM or a container, gets its own addressing:
- A dedicated /32 for IPv4.
- A dedicated /64 for IPv6.
On the host, each of those workload addresses is expressed as a static route pointing at the workload’s TAP interface. The workload sits behind its own bridge, isolated from every other tenant on the same host. There is no shared segment for tenants to see each other on, which means there is no broadcast domain to spoof into. ARP and ND spoofing between tenants stop being possible because there is no shared ARP or ND domain in the first place. The attack surface is removed by design rather than filtered after the fact.
This is the key inversion. In the old model, isolation was something you tried to enforce on top of a shared medium. In the new model, isolation is the default and connectivity is something you explicitly route.
Per-workload bridges and the interconnect problem
Giving each workload its own bridge and its own /32 and /64 solves the security model, but it creates an automation problem. If every host-to-workload link needs its own subnet, you are now managing an enormous amount of point-to-point addressing, and provisioning a workload means allocating, tracking, and reclaiming interconnect prefixes. That does not scale and it does not automate cleanly.
We solved it with link-local addressing. The interconnect between the host and each VM or container uses link-local IPv4 and IPv6 only. There is no globally significant addressing burned on the point-to-point link at all.
The practical payoff is large. Because link-local addresses are scoped to the link, the same address can sit on every TAP interface on the host side. There is no per-link allocation, no interconnect IPAM, and no risk of overlap. Every host-side TAP looks identical from a configuration standpoint, which means the provisioning logic for the link is the same for the first workload and the ten-thousandth. The workload’s actual reachable identity, the /32 and the /64, is carried as a route, not as an interface address on a shared subnet.
This is what made the rest of the automation tractable.
Automating guest configuration across distros with cloud-init
The next obstacle was inside the guest. A hosting provider does not get to pick the operating system. Customers run Ubuntu across several versions, AlmaLinux, CentOS, and a long list of others, each with its own opinion about network configuration. Netplan, NetworkManager, ifupdown, systemd-networkd, and various legacy scripts all coexist in the customer fleet. Writing and maintaining a per-distro network configuration for an L3-attached, link-local interconnect model would have been an endless maintenance treadmill.
We standardized on cloud-init. Instead of shipping distro-specific network scripts, the workload is provisioned with a single cloud-init configuration that expresses the network intent in a portable way. Cloud-init is supported across effectively every mainstream cloud image, so one template covers the fleet. The same configuration brings up the link-local interconnect, installs the workload’s routing, and configures the /32 and /64 the same way regardless of whether the guest is Ubuntu, AlmaLinux, or CentOS underneath.
This collapsed a sprawling per-distro problem into a single artifact that provisioning automation can render and inject at deploy time. New OS images join the platform without bespoke network plumbing.
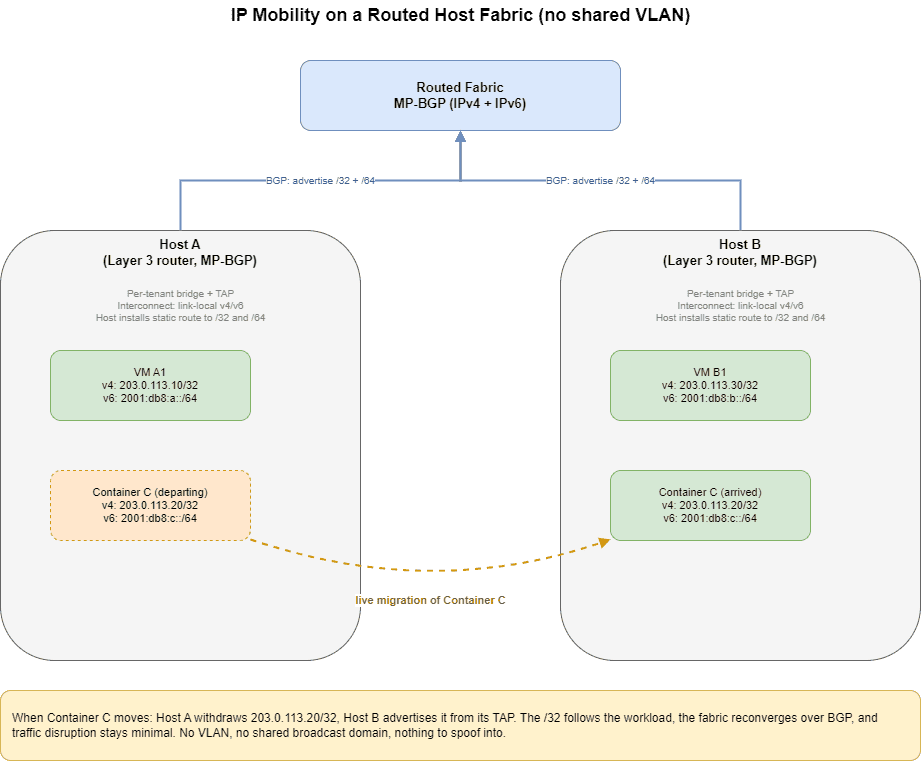
How IP mobility falls out of the design
Here is where the architecture pays a dividend we did not have to engineer separately. The same routing model that removed the Layer 2 attack surface also gave us live IP mobility.
Each host redistributes its workloads’ /32 and /64 routes into the fabric over BGP. The route exists only as long as the workload exists on that host. The lifecycle looks like this:
- A container or VM is deployed on a host. The host installs the static route toward its TAP interface and redistributes the /32 and /64 into the fabric. The rest of the network learns how to reach the workload.
- The workload is shut down. The static route is removed, the redistribution stops, and the route is withdrawn from the fabric. There is no stale reachability and no lingering ARP entry on a shared segment to clean up.
- The workload is redeployed on a different host. The new host installs the static route and advertises the same /32 and /64. The fabric learns the route from the new host and converges.
The result is that a workload’s IP address is no longer tied to a physical location. It follows the workload. When a container migrates from one host to another, the address moves with it, and the fabric simply relearns the path. Convergence is bounded by BGP, not by waiting out ARP timeouts or flushing CAM tables across a broadcast domain, so the traffic disruption during migration is minimal.
That is IP mobility achieved with standard routing, no overlay encapsulation tax on the data path, and no Layer 2 extension stretched across the network. The IP is mobile because it was never anchored to a segment to begin with.
What this architecture buys you
Stepping back, the design delivers several things at once that the shared VLAN could never offer:
- Tenant isolation by design. With no shared broadcast domain, the classic Layer 2 inter-tenant attacks are structurally impossible rather than filtered.
- Clean dual-stack. MP-BGP carries IPv4 and IPv6 together, and every workload gets both a /32 and a /64 with the same provisioning path.
- Scalable, boring interconnects. Link-local addressing on every TAP means there is no interconnect IPAM to manage and every host-side link is identical.
- Portable guest config. One cloud-init template covers a heterogeneous OS fleet instead of a pile of per-distro scripts.
- IP mobility for free. Workload addresses follow the workload across hosts, with convergence handled by BGP and minimal traffic disruption on migration.
Trade-offs worth naming
This design is not free of cost, and it would be dishonest to pretend otherwise.
You are moving complexity from the data plane into the control plane and into automation. Every host becomes a router, which means your fabric now carries a host route per workload. That has to be sized and bounded. You need to think about route scale, BGP session count, and how aggressively you summarize, because a /32 and /64 per workload across a large fleet is a lot of state. The honest answer is that this scales well for the workload counts a hosting provider in this segment actually runs, but it is a number you must plan for rather than assume.
You also take on a hard dependency on automation. A Layer 3 host model with per-workload routing and cloud-init provisioning is only operable if the provisioning, the route lifecycle, and the guest configuration are fully automated and observable. Done by hand it would be worse than the shared VLAN. Done with proper automation, it is dramatically more secure and more flexible.
For this customer, those trade-offs were clearly worth it. The shared VLAN was costing them in security exposure and in the constant effort of trying to police a medium that was never designed to be policed. The routed model removed the exposure, simplified provisioning, and handed them workload mobility they did not have before.
Closing thought
The instinct when a shared segment gets attacked is to add controls to the segment. More ACLs, more inspection, more filtering at the hypervisor. Sometimes the better engineering answer is to remove the thing being attacked. Routing each workload as its own /32 and /64, attaching it over a link-local interconnect, and letting BGP carry the reachability turned a fragile shared broadcast domain into an isolated, automatable, mobile fabric.
If you are running multi-tenant compute on a shared VLAN today and spending your time hardening it, it is worth asking whether you are maintaining the right design or just maintaining the wrong one more carefully.
ITcare designs and operates routed access and fabric architectures for ISPs, data center operators, and cloud and hosting providers. If you are weighing a move off shared Layer 2 for your multi-tenant network, this is the kind of work our Professional Network Services team does
be our next success story!
Drop us a line! We care for your Business and are here to answer your questions 24/7